
Deep Learning for Kaggle Competitions
Reading Time:

In this series we are going to pretend we entered a kaggle competition and want to submit a finished product. I will show you a couple of different ways to do that. For now most examples will use the Pytorch package. This first post is a primer, so to speak, to understanding the process of how you should approach the competitions

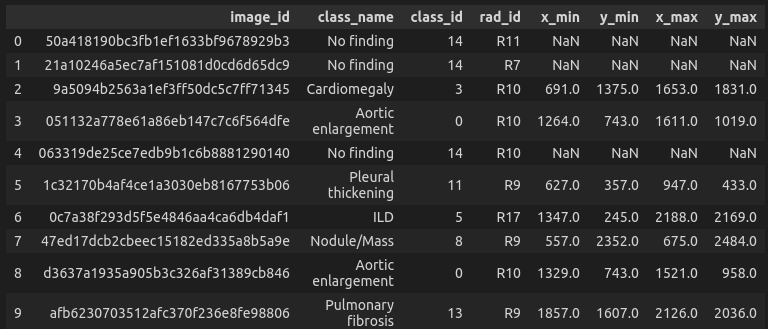
After joining the competition and reading the description, looking at data, and understanding the evaluation, you can fire up your favorite python editor and start importing packages. Though this competition has a dataset composed of dicom images that are over 128 gb in size, some nice person wrote a script and saved the dataset to a more palatable 50gb of png images. Now on to looking at the data. The data is comprised of a csv file with the image id and classification data, along with other bounding box metadata that we won't look at at this point.
So now that we took a minute to see the data structure and the image themselves, we need to create a dataset and a dataloader. Think of the dataset as the truck that is connected to a dataloader that acts as sort of a moving belt to transport the contents to be processed.We can create some classes for these concepts.
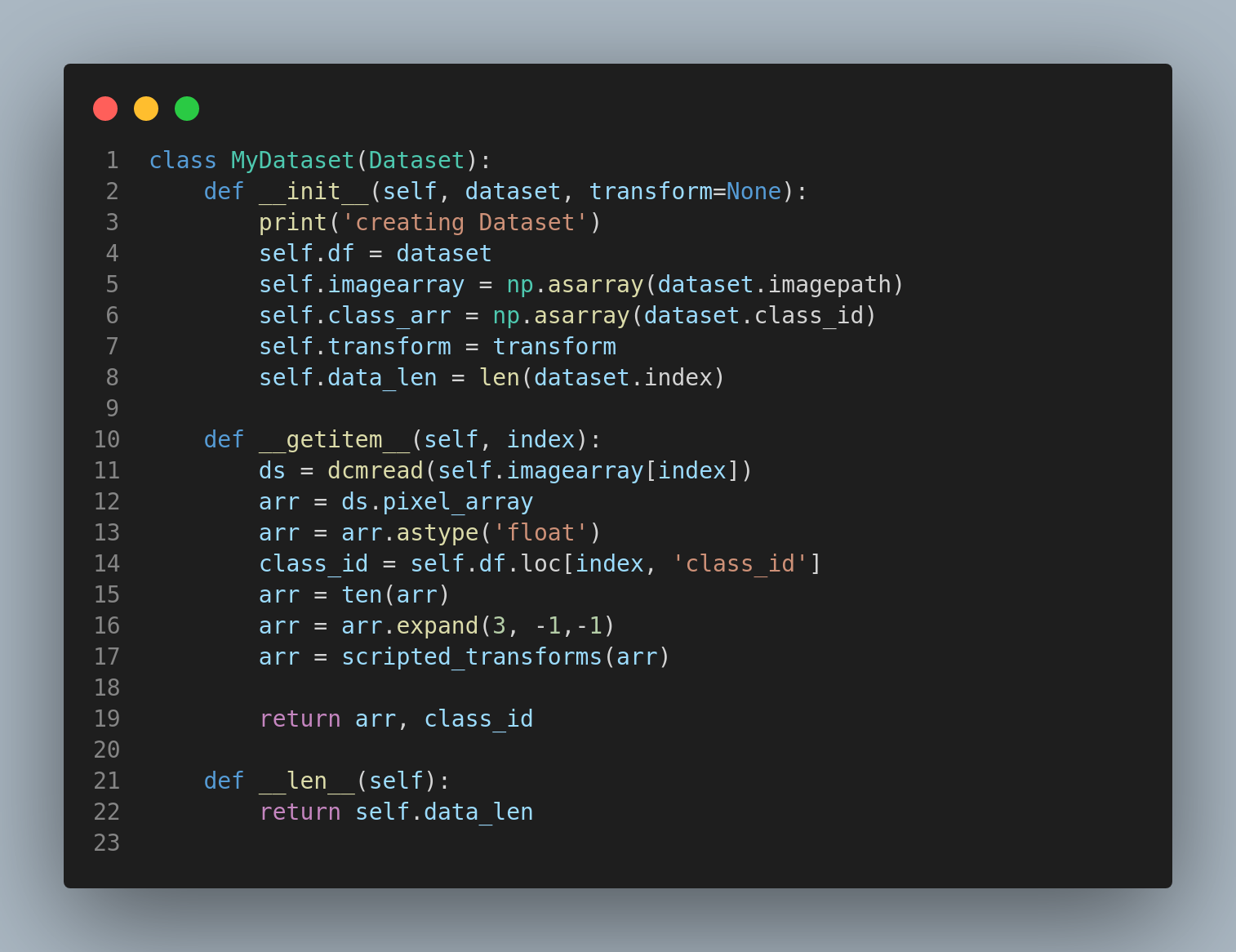
Now that we determined how the data is going to be collected for processing(the dataset class, we are going to initialize the class by assign it to a variable and the passing that variable to a variable that initialized a Dataloader class. Remember your python training, the class is just the blueprint while actual object is the variable that became the physical function of the blueprint.
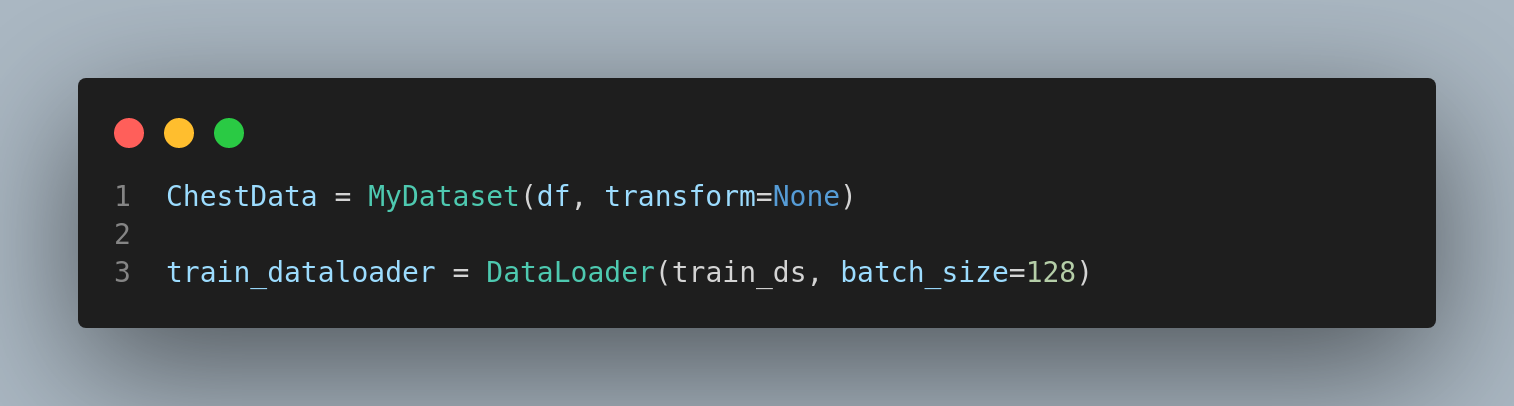
This is really a deep dive subject but suffice it to say the model is a complex function that is making a best guess as to the what class should the image belong to. Its an extreme oversimplification but this is a primer after all.
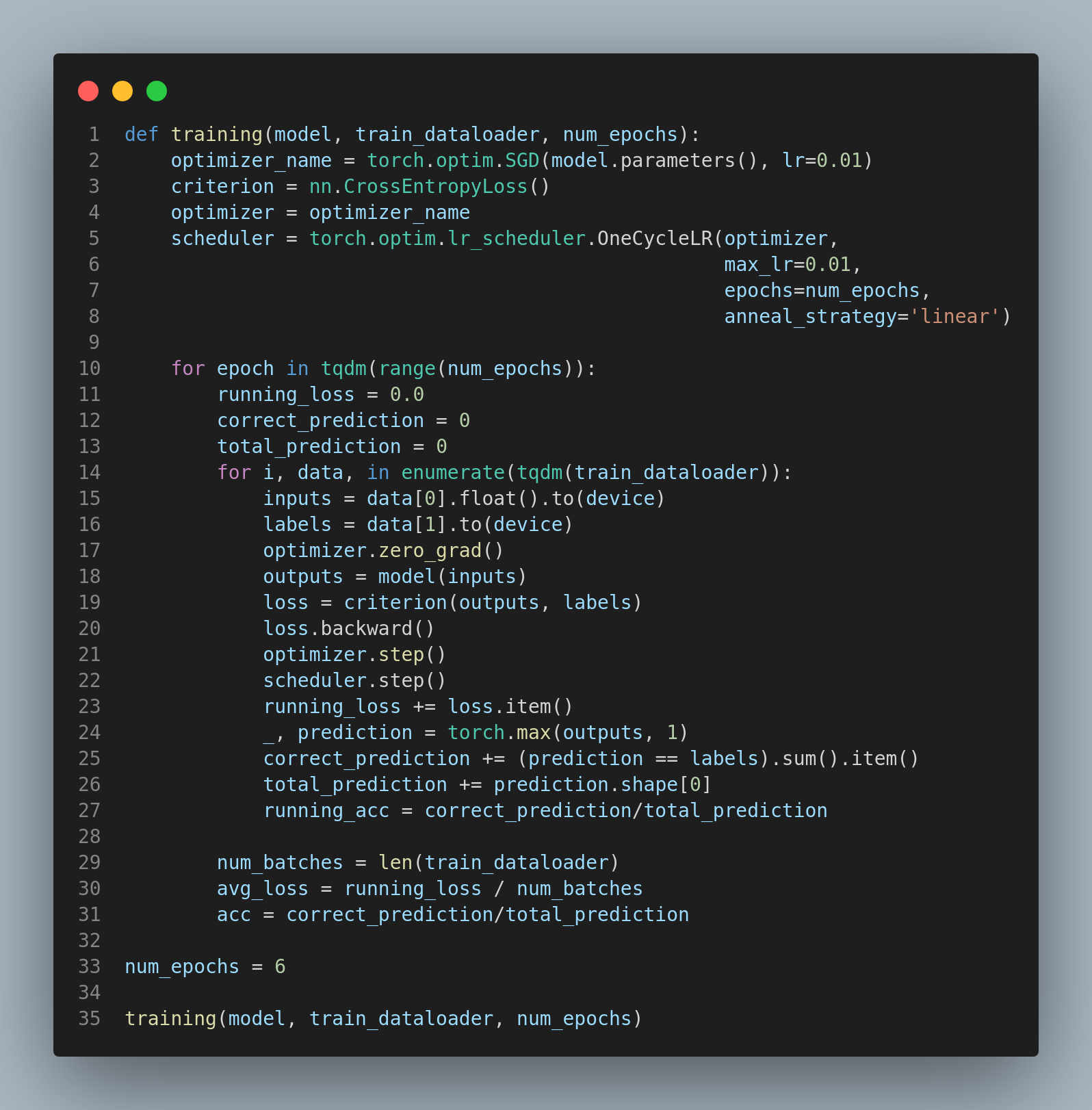
The model can't do everything on its own so there needs to be a way to have the data enter the model more than once and adjust the paramerters of the model based on a metric, the loss function. This is where the training function comes. It takes all the other functions that we created and passes the full dataset through the model multiple times and calculates an accuracy, though it truth it could be and should be another metric
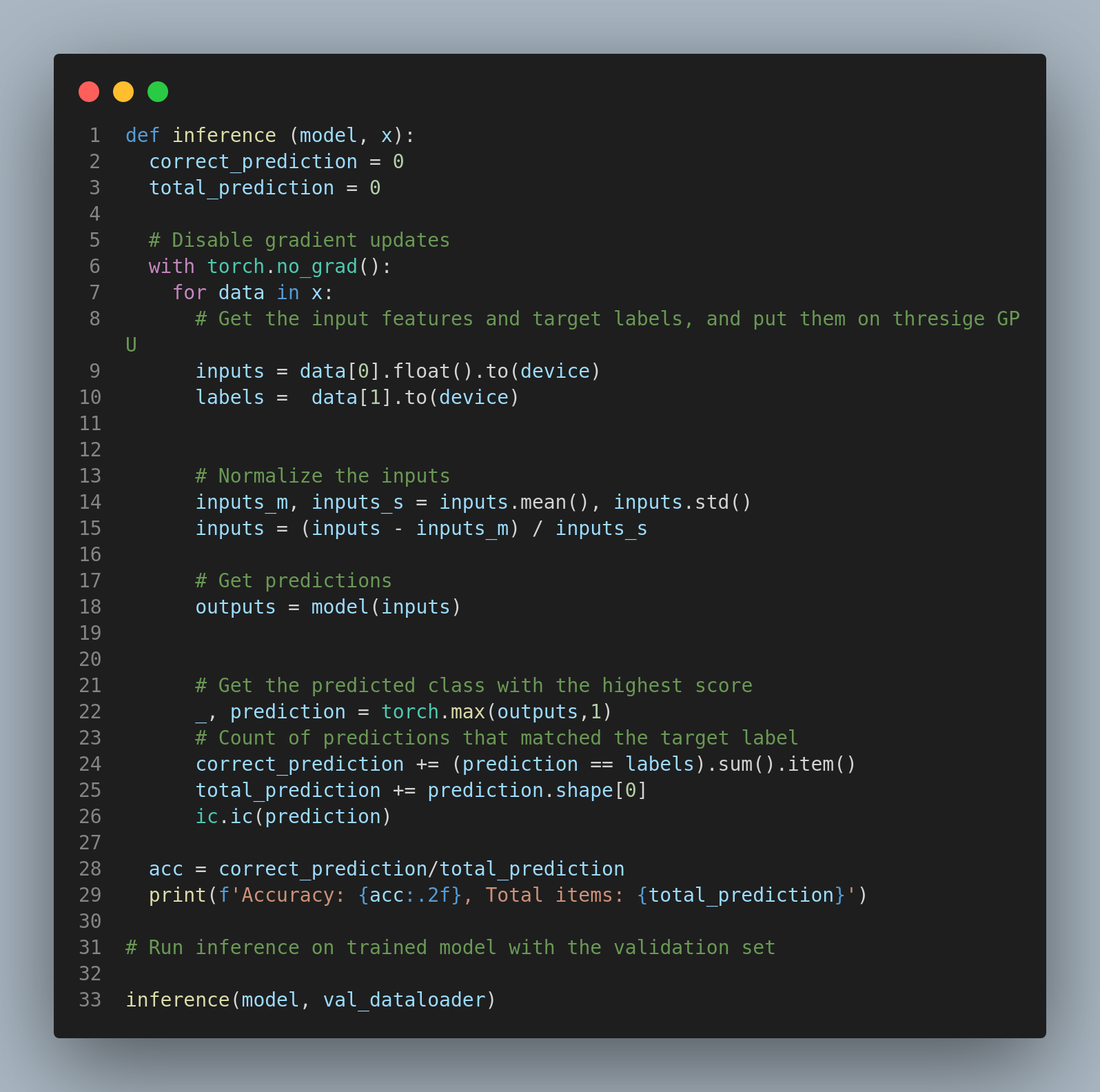
Now we validate our trained model accuracy on part of the dataset that was separated from the main dataset. The model hasn't seen this data at all so it's like a new set of images to classify. This is where you compare the training accuracy to the validation accuracy. The similiarities or the disimilarities can tell help you plan your strategy for the next round of training(from scratch) and what kind of adjustments you need.
Now you have a trained model that can accept data, for example, a previouly unaccessable similiar dataset that Kaggle will use to test the robustness of your model and rank you among other Kagglers. This is your baseline. Now you can do things like closely analyze the data, modify and manipulate the dataset, tune hyperparameters of the model, and other strategies to squeeze the last bit of performance of the model.
To Summarize


